
A Linux computer contains several files, which include data files, directories, system files, library files, and other different types of files. These files are stored and organized in directories and subdirectories. The file systems do not rely on the actual data of a file but on the file and directory data structures. Linux maintains file system entries of these files and directories, and these entries are described by inode.
In this tutorial, we will learn about the inodes in Linux and how it works.
What is Inode?
Inode or index node is a Linux data structure that describes the objects of file systems, which include files and directories. An inode contains a record of file and directory location in the file system, their names, owner account, and permissions. This information is called metadata and is significant for the inner functioning of the Linux operating system.
In a Linux file system, the directory entry structure and inode provide a framework to store file and directory metadata. This metadata is available for Linux Kernel, user applications, system utilities, and commands. The same inode details are usually stored at the beginning of the partition in a tabular format.
Every disk partition has its own inode table and the inode numbers are unique inside the particular partition. When a new file is created, an inode number is assigned to the file. Further information about the file is retrieved by referencing the file’s inode number from the inode table. If all the inode numbers are occupied and you run out of inodes, then Linux operating system does not allow you to store or create any new files.
Inode Contents
The inode data structure stores all the metadata about a file or directory, except for the file name and the file data. The following attributes are some of the most common file metadata:
- Device ID- Unique identifier of the device that contains the file.
- User ID- Identifier of the user that owns the file.
- Group ID- Identifier of the filegroup that owns the file.
- File Size- Size of the file in the number of bytes and blocks allocated to the file.
- Access permissions- Read, write and execute permissions of the file for the owner, group, and rest of the world.
- Owner/Group- Owner and group names of the file.
- File location- Physical location of the file on the disk.
- Timestamps- Different timestamps to indicate inode modification time (ctime), file modification time (mtime), and file last access time (atime).
You can use Linux command-line utilities such as stat, ls, and df to display some or all of the above metadata.
How is Inode Useful?
An inode is the basis of a Linux file system. It manages file and directory metadata and is essential for the functioning of a file system. The inode is required to check the file system object locations, modification dates, size, and other relevant information.
When an application refers to a Linux file or directory by name, then the OS accesses the inode. The inode provides data and information to the OS to perform operations.
If all the inodes in your system are occupied, then you will not be able to store any more files on your hard drive, even if free space is available.
Inode Number
Inode number is a unique numeric string assigned to each Linux file and directory. It is unique within the file system of the file or directory, and the same inode number cannot be assigned to another file in the file system.
If you ever see the same inode number assigned to another file in a different file system, then it is still unique in the overall system. The inode number, in combination with the file system identifier, creates a unique ID for a file system object. This method makes it impossible for two files to have conflicting inode numbers.
You can list inode numbers of all the files in the given file system using the following ls command:
ls -i
The inode numbers are listed for all the file system objects in the current directory. These inodes store metadata, pointers to the hard disk blocks, and the location of the file system objects.
Small files do not require additional inode entries. If a file is very large and is fragmented, then some inode blocks might point to other disk blocks. Some other disk blocks might have pointers to further disk blocks. This mechanism solves the inode size problem and can store several disk block pointers.
How Does the Inode Work?
An inode number and a file name are assigned to each new file or directory. The file name and inode number are stored in a directory. When you list these files using the ls -i command, you can see the file name and inode number.
At the same time, a new entry is created in the inode table for each inode number. The entry for the inode number contains file metadata, such as size, modification dates, device ID, and other relevant information.
Use the following df command to display a list of file systems, how many inodes they contain, how many inodes are used, and file system mount points:
df -hi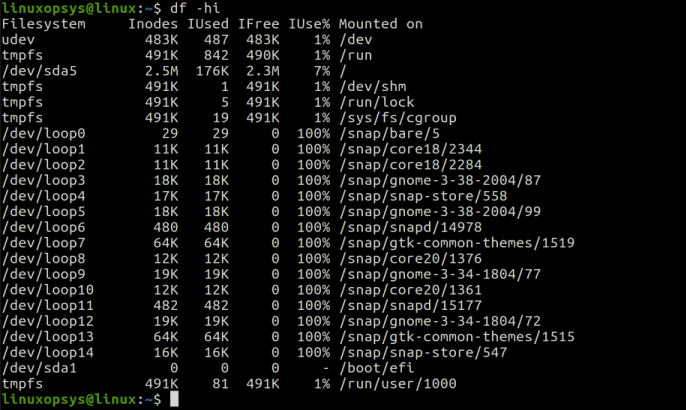
In this output, we can also see the total number of free inodes and you can make sure you do not run out of inodes.
Inode and Hard/Soft Links
When you create hard or soft links, a new file is created. However, the inode works differently for both hard and soft links.
When you create a soft link for a file or directory, the link file has a different inode number than the original file. Whereas, in the case of a hard link, the original file and the link file both have the same inode number. This is because the hard link provides a new name to the same data and thus can be accessed using the same inode number.
Inode of a File
Every file is assigned an inode number when you create it. This inode number refers to the metadata information stored in the inode table. Use the following command to display inode information of a file:
stat users.txt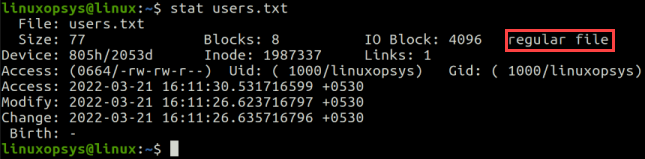
In this example, we can see the file name, its size, device ID, inode number, access privileges, and various timestamps. This output also shows the file type, which is a regular file. Regular files also have these metadata associated with them.
Inode of a Directory
The Linux file system treats every object as a file and thus similar to a file, the inode number is also assigned to a directory when it is first created. Use the stat command to display inode information of a directory:
stat Pictures/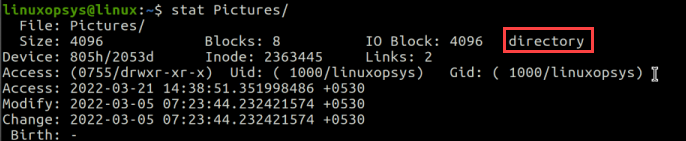
Here the same information is displayed as for a file, but the object type is displayed as a directory.
Inode System Level
When a Linux or UNIX-like file system is created, an inode table is also created along with it. This inode is an index of every file in the particular file system.
Every computer contains many inodes and usually does not occupy all inodes. However, there are two numbers that you must watch for. First is the maximum number of inodes, which is generally almost 1 percent of the total disk space allocated to the file system. Second is the number of occupied inodes on your system.
At the system level, Linux labels even the smallest units of data and indexes them using inodes. When an application or system utilities require to open or read these indexed files, they go to the inode table and find out the location of the particular file on the disk. So this is one of the most important data structures that are extremely important for the inner working of the Linux operating system.
Conclusion
In this tutorial, we learned about inodes, their contents, and how they are useful. Every file or directory entry corresponds to an inode number that is assigned to the specified file or directory. This information comes in handy when you need to find the location of a particular file. Generally, this data structure is accessed by the operating system, but you can see inode information of a particular file or directory using the stat command.


Comments