
Most developers work with binary data and it is helpful for them to know about the data if they can read the data in a human-readable format.
In this tutorial, we learn about how to use hexdump command with examples.
What is Hexdump and what does it do?
Hexdump is a popular Linux command which can be used to display the contents of the file in a specific human-readable format. It can dump contents into various formats such as hexadecimal, ASCII, octal or decimal. It is normally used to analyze machine code by security or malware analysts or compiler programmers.
Generally used to analyze:
- File from a disk device.
- To read partition or filesystem structure from a disk
- Data captured from network or serial line.
- From a memory dump.
The command expects the user to specify a file or any standard input as an input parameter and converts it into a specific format as per the user's need.
There is also an alternative to the hexdump command such as xxd and od which takes the input to different formats.
Hexdump utility comes pre-installed in all Linux distributions. It is provided by bsdmainutils package on Ubuntu.
How to use Hexdump Command
In this section let us understand various hexdump command options with an example. let us get started!
Let us explore various options used with the hexdump command with an example.
hexdump -b
Using "-b" switch with hexdump will display the input offset in hexadecimal format. This option is also called "One-byte octal display". The output will be followed by sixteen space-separated, three-column, zero-filled, bytes of input data, in octal, per line.
hexdump -b <filename>Here is the example output we received when we run this command with "-b" switch on a file named "hexdump.txt".
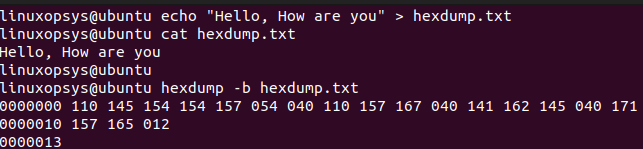
Where,
First column: input offset in file.
Second column: hexadecimal equivalent of the data.
hexdump -c
This option is referred to as "One-byte character display". You can use this command parameter to display the input offset in hexadecimal. The output string will be followed by sixteen space-separated, three-column, space-filled, characters of input data per line.
hexdump -c <filename>
hexdump -C
Also known as "Canonical hex+ASCII display", this shows the input offset in hexadecimal, the output is followed by sixteen space-separated, two-column, hexadecimal bytes, along with the same sixteen bytes in %_p format enclosed in ``|'' characters.
hexdump -C <filename>Here is a working example of this command option.

You may use echo command to pass a string and read hexadecimanl values for each character.
For example
( echo "welcome"; ) | hexdump -C hexdump -d
This option shows the input offset in hexadecimal, along with eight space-separated, five-column, zero-filled, two-byte units of input data. The output is in unsigned decimal per line. It is also referred to as "Two-byte decimal display" mode.
hexdump -d <filename>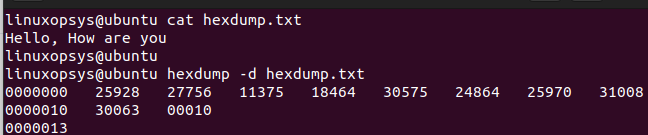
hexdump -o
Also known as "Two-byte octal display", it shows the specified input offset in hexadecimal. The output of the command is followed by eight space-separated, six column, zero-filled, two byte quantities of input data, in octal, per line.
hexdump -o <filename>
hexdump -x
It shows the offset in hexadecimal, followed by eight, space separated, four-column, zero filled, two-byte quantities of input data, in hexadecimal. It is referred to as "Two-byte hexadecimal display".
hexdump -x <filename>
hexdump -v
By default, hexdump uses the asterisk sign (*) to replace the identical line in the output string, but -v option causes hexdump to display all input data. This option is useful when performing the analysis of complete output of any string or text. This command can be used in shell/bash scripts as well for better automation of your desired tasks.
hexdump -v <filename>hexdump -s
This option is used to dump only a specified number of bytes from an input file. It skips the first 'n' bytes of input data and displays the rest.
hexdump -s -n -c <filename>where n is the number of lines to be displayed.
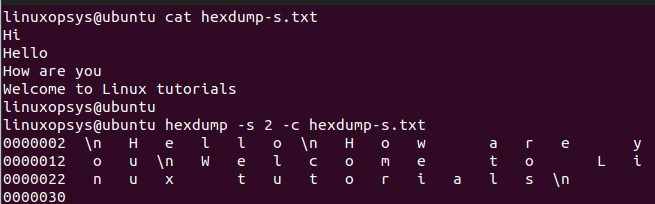
In the output, you can see that the first two lines from the input file have been skipped and the rest of the data is displayed.
hexdump -e
This option is used to specify a format string to be used for displaying data. This helps the user to read the output better as it provides good formatting options.
hexdump -e format_unit format_stringhexdump with -e option can be used with a character "%_p" which specifies hexdump to print a character in the system's default character set.
Example
hexdump -v -e '"%010_ad |" 16/1 "%_p" "|\n"' datafile.txt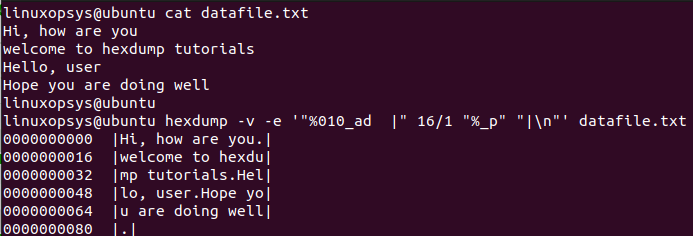
In the output, you will see that the current decimal byte offset is set to 10 digits with 0's followed by a "|" character and 16 items each with 1-byte size and a "|" character and a new line.
hexdump options
In this section, let us take a look at different hexdump options and understand them.
| Options | Description |
|---|---|
| default | One-Byte Hexadecimal. rows of 16, two-digit, hexadecimal bytes. |
| -b | One-byte octal display. Displays the input offset (address) of data in hexadecimal format. It is followed by sixteen space-separated, three-column, zero-filled, bytes of input data, in octal, per line. |
| -c | One-byte character display. Display the input offset in hexadecimal, followed by sixteen space-separated, three-column, space-filled, characters of input data per line. |
| -C | Canonical hex+ASCII display. Display the input offset in hexadecimal, followed by sixteen space-separated, two digit, hexadecimal bytes, followed by the same 16 bytes in ASCII if printable or a dot if unprintable. Calling the command hd implies this option. |
| -d | Two-byte decimal display. Display the input offset in hexadecimal, followed by eight space-separated, five-column, zero-filled, two-byte units of input data, in unsigned decimal, per line. |
| -e | format_string Specify a format string to be used for displaying data. |
| -f | format_file Specify a file that contains one or more newline-separated format strings. Empty lines and lines whose first non-blank character is a hash mark (#) are ignored. |
| -n | Length Interpret only length bytes of input. |
| -o | Two-byte octal display. Display the input offset in hexadecimal, followed by eight space-separated, six-column, zero-filled, two-byte quantities of input data, in octal, per line. |
| -s | Offset Skip offset bytes from the beginning of the input. By default, the offset is interpreted as a decimal number. With a leading 0x or 0X, an offset is interpreted as a hexadecimal number, otherwise, with a leading 0, an offset is interpreted as an octal number. |
| -v | Cause hexdump to display all input data. Without the -v option, any number of groups of output lines, which would be identical to the immediately preceding group of output lines (except for the input offsets), are replaced with a line comprised of a single asterisk. |
| -x | Two-byte hexadecimal display. Display the input offset in hexadecimal, followed by eight, space-separated, four-column, zero-filled, two-byte quantities of input data, in hexadecimal, per line. |
For more details please check out the man page of the hexdump command.


About The Author
Bobbin Zachariah

Bobbin Zachariah is an experienced Linux engineer who has been supporting infrastructure for many companies. He specializes in Shell scripting, AWS Cloud, JavaScript, and Nodejs. He has qualified Master’s degree in computer science. He holds Red Hat Certified Engineer (RHCE) certification and RedHat Enable Sysadmin.
What would be canonical format `-C` using generic format string `-e`?
I suggest
hexdump -e ‘”%08_ad ” 8/1 “%02x ” ” ” 8/1 “%02x ” ” |” -e “16 “%_p” “|\n”‘