
grep is a text-processing tool. It stands for Global Expression Print. As a Linux user, you can use grep to search files and directories. You can use it to match patterns and print output to the terminal.
However, grep with regex (regular expression) can change how you approach pattern searching and matching. That’s because regex is an advanced output-filtering tool that lets you input a sequence of characters for matching.
Regex also works with other Linux commands, such as awk and sed commands, making it an ideal search choice.
In this guide, we’ll look closer at grep and regex. We’ll use both of them to do advanced text searching and filtering.
Pre-requisite to follow the tutorial
To follow the tutorial, you’ll need to have the following:
- First, have a basic understanding of Linux. If you’re new, check out the Linuxopsys beginner’s Linux tutorial to get started.
- Access to working command line/terminal.
- Access to a text file to run the examples.
- Basic understanding of grep command usage.
grep syntax
The syntax of grep is as below.
grep -options [regex] [file]Also, you’ll need to know about three regex syntax options. These include:
- Basic Regular Expressions (BRE)
- Extended Regular Expressions (ERE)
- Pearl Compatible Regular Expressions (PCRE)
Notes:
- When you use grep, it uses BRE as default.
- When working with basic regular expressions, the metacharacters such as + , | , ? , { , ( , and ) are interpreted as they are. So, if you want to use the characters, you’ll need to use the backslash (\) as an escape character.
Grep and Regex in Action
Now that we have a complete grip on grep, it’s time to see grep and regex in action. In this section, we’ll learn about them with examples.
Let’s get started.
1. Do a basic grep word search, doing literal matches
A word is also a regex. So, let’s do a basic grep search with it.
The syntax to do so is:
grep [regex] [filename]$ grep fruit fruits.txt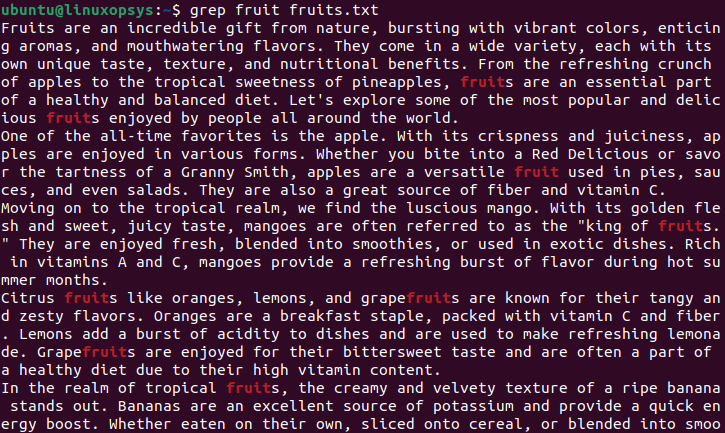
Let’s take inside the .bashrc file with grep.
$ grep if .bashrc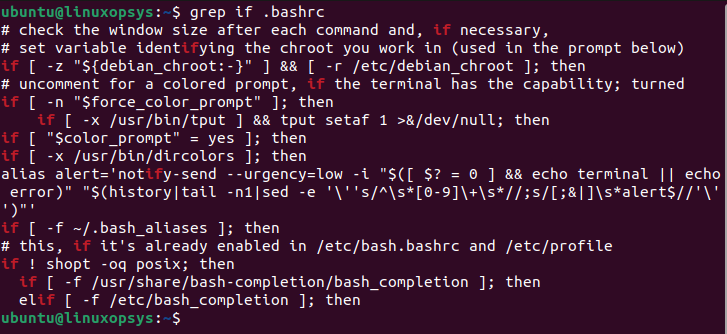
And, if you want to show the current users by including lines that contain the “bash” word in the /etc/passwd file, run the following grep command.
$ grep bash /etc/passwd
These examples show the most basic use of the grep command. Here, it searches for literal characters or sets of character.
2. Anchor Matching
Anchor matching is a valuable technique. Here, you use anchors (meta-characters) to refine your search. These anchors include:
- ^ caret sign: The caret (^) sign looks for an empty string that is present at the beginning of a line.
- $ dollar sign: The dollar ($) sign does the opposite of the caret symbol and looks for an empty string at the end of a line.
Let’s see each of them in action to understand their use-case better.
You can use the ^ sign to search for lines that start with a specific string. So, if you want to search for lines that start with berries, you’ll need to write the command below.
$ grep ‘^Moving’’ fruits.txt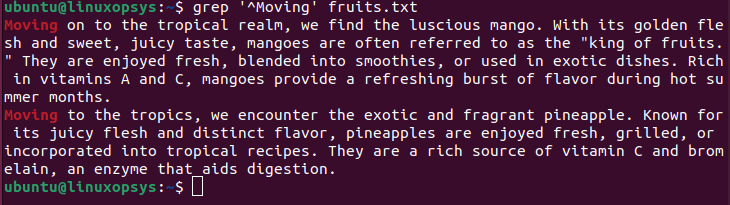
Note: It is case-sensitive. So, if you use the ‘^moving’ regex to search, it would return nothing or something else, depending on your text file.
Similarly, you can use the $ symbol to print out lines that end with your preferred string value.
So, if you want to return a line that ends the word ”digestion.” (yes, there is a dot at the end of the string), you’ll need to run the following command.
$ grep ‘digestion.$’ fruits.txt
You can combine both to find sentences that start and end with the same word.
$ grep ‘^Moving$’ fruits.txt3. Using Character Classes and bracket expressions
Character Classes in regex are a set of characters. It is represented within square brackets. The LC_TYPE locale determines the character class interpretation. These character classes include:
- [:alnum:] - This character class consists of alphanumeric characters.
- [:alpha:] - This character class comprises alphabetic characters.
- [:blank:] - This character consists of blank characters, usually tab and space.
- [:cntrl:] - This character class consists of control characters.
- [:digit:] - It consists of digits 0 to 9
- [:graph:] - This character class comprises graphical characters. It includes [:alnum:] and [:punct:] - (punctuation characters).
- [:lower:] - It consists of lowercase letters.
- [:upper:] - This character class consists of upper-case letters.
- [:print:] - This class comprises printable characters, including [:alnum:], [:punct:], and space.
- [:xdigit:] - It comprises hexadecimal digits. For example, (0 1 2 3 4 5 6 7 8 9 A B C D E F a b c d e f).
Let’s see an example to understand it.
Let’s search for all characters that start with upper-case.
$ grep [[:upper:]] fruits.txt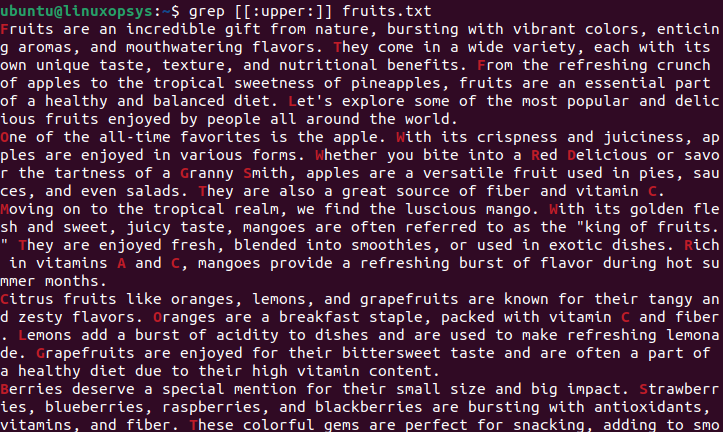
Now, let’s search for digits within the file.
$ grep [[:digit:]] fruits.txt
If you see the screenshot above, we also have alphanumeric characters; let’s search for them with the [[:alpha:]] class. It’ll also list alpha characters in different colors.
$ grep [[:alpha:]] fruits.txt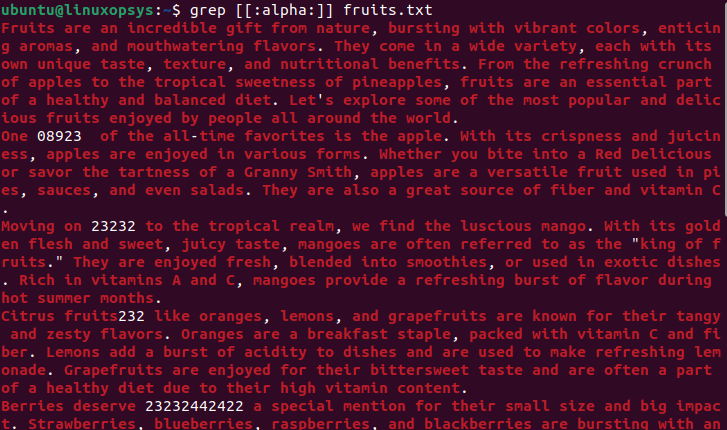
We also have bracket expressions. These are used to match characters or a group of characters.
So, if you want to search for lines that contain two words, accept and accent, you’ll need to run the following command.
$ grep ‘acce[np]t’ fruits.txt4. Grouping
Grouping in regex is a way to group multiple patterns in one. Here, we’ll need to use parentheses() metacharacter so, if you want to create a group such as (mon) that includes the letters “m,”o,”n” -- treating multiple characters as a single unit.
You can use the group by escaping it in a basic or extended regular expression.
Let’s see an example to understand it.
$ grep 'script\(ing\)\?' linux.txt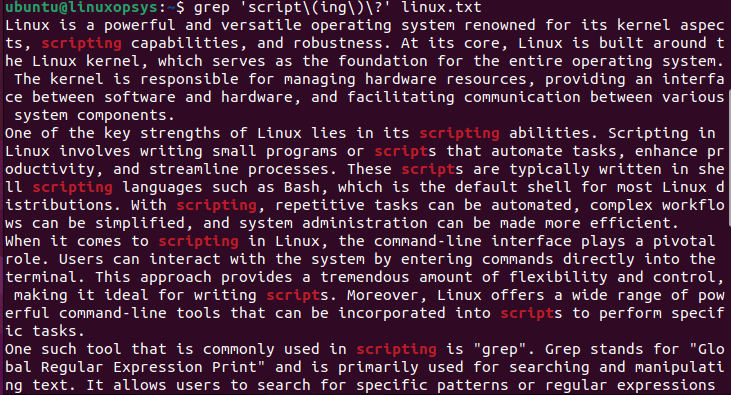
Let’s see other examples in action.
Matching repeated patterns
You can use grouping to match repeated patterns, for example.
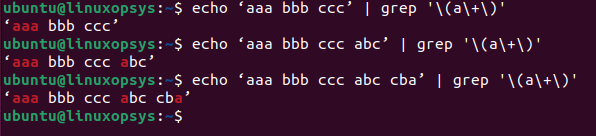
$ echo ‘aaa bbb ccc abc cba’ | grep '\(a\+\)'This will return any instances that contain one or more “a” character occurrences.
Capturing groups
If you want to capture groups rather than a character instance, you’ll need to use a different regex approach.
$ echo 'abc123 ab123c abc12345' | grep "\(abc\)\(123\)"As you can see, it searches for grouped characters.

Alternatives within a group
Using grouping in regex, you can also search for alternatives. This way, you can search for multiple groups of characters throughout the text.
$ echo "apple orange banana" | grep "\(apple\|orange\)"
This command matches and prints "apple" or "orange" from the input. The output will be "apple" and "orange."
Non-capturing groups
Lastly, you can use non-capturing groups with ?:
You can put the ?: within the parentheses, creating a non-capturing group.
$ echo "hello" | grep "\(?:he\)llo"It still groups the pattern but doesn't capture it as a separate group. So in this example, it matches and prints "hello."
5. PCRE
PCRE stands for Perl Compatible Regular Expression. It is the most-compatible library written in C. It implements the regular expression engine with PERL programming capabilities.
You can use PCRE to do much more than basic regular expressions. For example, you can use ‘\d’ as a short form of ‘[0-9]’ for digits finding.
Let’s go through the examples below.
Matching an email address
You can use PCRE to match your email address. This is a tricky regex and grep usage, but it gets the job done. So, if you’re writing a script or an app that needs to identify the email address, you can use the following approach.
$ echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
This command matches and prints the email address in the given input. It uses a PCRE pattern to match the standard email address format.
Matching a date in YYYY-MM-DD format
Similarly, you can use the PCRE pattern to match a date in YYYY-MM-DD format.
$ echo "The event is scheduled for 2023-05-20" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
This command matches and prints the date in "YYYY-MM-DD" format from the given input. The PCRE pattern matches four digits, followed by a hyphen, two digits, another hyphen, and two more digits.
Using positive lookahead
You can also use the PCRE pattern to look ahead for a word or string and only print if it is found.
$ echo "I love coding and programming" | grep -P "coding(?=\s+and)"This command matches and prints the word "coding" only if followed by the phrase "and" with one or more whitespace characters in between. The positive lookahead assertion (?=\s+and) ensures that the match is made only if the lookahead condition is met.
6. Extended Regex
Extended regex removes the need to add escape characters in the patterns. This means these are not interpreted as literal characters.
By default, grep defaults to basic regex. To use extended regex, you must use the -E flag.
$ grep -E 'ap+les' fruits.txt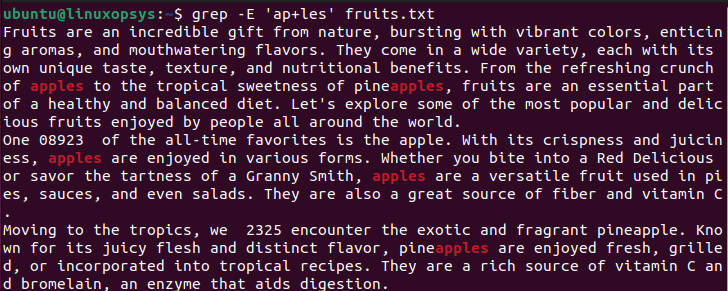
Searches for lines in the file fruits.txt that contain the pattern 'ap+les', where the letter 'a' is followed by one or more occurrences of the letter 'p', and then the letters 'les'
Similarly, you can use the ^ and $ signs without escaping them.
$ grep ‘^Moving$’ fruits.txt7. Alternation
Alternation is the simple means to define alternative matches. You’ll need to use the escaped pipe character (\|) to do so.
For example, you can search for the words “warning” and “error” in log files by running the following command.
$ sudo grep -l ‘warning\|error’ /var/log/*.logHere the alternation operator (|) in the regular expression 'warning\|error' allows for alternative matches, enabling the command to search for either 'warning' or 'error' in the log files.
8. Quantifiers
Next, we have Quantifiers. These refer to metacharacters that specify the number of match appearances. Some of these quantifiers include:
| Quantifier | Description |
| * (asterisk) | Zero or more matches |
| ? (question mark) | Zero or one match |
| + (plus sign) | One or more matches |
| {n} | n matches |
| {n, } | n or more matches |
| {, p} | Up to p matches |
| {n, p} | From n to p matches |
Let’s use the + symbol for one or more matches.
$ grep -E 'ap+les' fruits.txt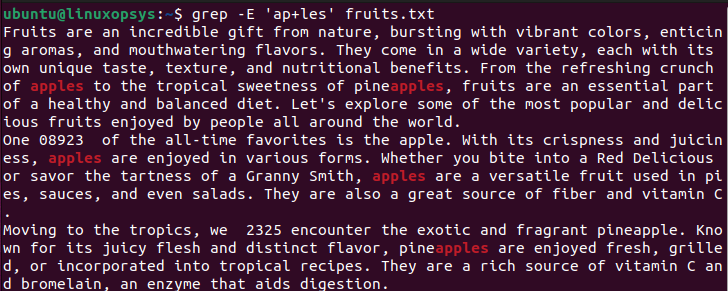
The -E option enables extended regular expressions, allowing the use of the + quantifier to match one or more occurrences of the preceding character or group.
Another example would be to use the * asterisk symbol for zero or more matches.
$ grep a*les fruits.txtThat’s it. We have come to the end of our grep and regex tutorial.


About The Author
Nitish Singh

Nitish Singh is a certified C1 Advanced(CEFR) tech writer from Kolkata, India. He has a proven track record of making tech accessible to everyone, with his work being read by over a million users worldwide. With a master’s degree in computer science and a history of research and publication, he has worked in various roles, such as content manager, news writer, blockchain writer, and Linux enthusiast. He loves Linux to its kernel and learns new Linux concepts daily.
Comments