
The wget command is a utility in Linux that is used for non-interactive downloading of files from the web. It supports downloading via HTTP, HTTPS, and FTP protocols.
In this guide, we learn about the wget command in Linux with examples.
Installing Wget
The wget comes preinstalled on many Linux distributions, and therefore you won't need to install it. In case found it is not installed, you can easily install it using the package manager that comes with your Linux distribution.
Install wget on Debian / Ubuntu:
sudo apt install wgetInstall wget on Fedora / Rocky Linux / AlmaLinux:
sudo dnf install wgetInstall wget on Arch Linux:
sudo pacman -Sy wgetInstall wget on SUSE Linux:
sudo zypper install wgetBasics of Wget
The basic syntax of wget command:
wget [OPTIONS] [URL]Where,
- [OPTIONS] : This changes the behavior of wget such as changing the directory to save the file, mirroring, recursion, etc.
- [URL] : This is the URL of the file or page to download.
The wget configuration file, which is typically located at /etc/wgetrc or ~/.wgetrc. One useful situation is when the server is behind a proxy, you can add proxy details in the config file.
Options
Here are some of the most commonly used wget command options.
| Options | Description |
|---|---|
-O (Uppercase) | Downloads a file using a different file name |
-b or --background | Downloads a file in the background and frees up the terminal |
-i, --input-file | Allows to specify a list of URLs in a file to download. |
-c ( Lowercase ) | Resumes download of a partially downloaded file |
-P | Specifies the directory that a file will be downloaded |
-r or --recursive | Tell wget to follow links and download recursively. |
-N or --timestamping | Only download files that are newer than existing files. |
-m or --mirror | Downloads a mirror copy of a website including all website files. Equal to It's equivalent to -r -N -l inf --no-remove-listing. |
-np or --no-parent | Don't ascend to the parent directory when retrieving recursively. |
-k or --convert-links | Make links in downloaded HTML or CSS point to local files. |
-p or --page-requisites | Get all images, etc. needed to display HTML page |
--limit-rate | Limits download speed when downloading a file |
--ftp-user=USER | Set FTP user to USER |
--ftp-password=PASS | Set FTP password to PASS |
--no-check-certificate | Skips SSL certificate checking |
--user-agent | Changes browser UserAgent |
-o or --output-file | Log output of wget to a file, use -a option to append. |
-V, --version | Displays the version of wget |
-h, --help | Displays all the wget command options and usage |
Downloading a file using wget
To download a file simply pass the specified URL as argument to the wget command.
Example:
wget https://files.phpmyadmin.net/phpMyAdmin/5.1.1/phpMyAdmin-5.1.1-all-languages.zip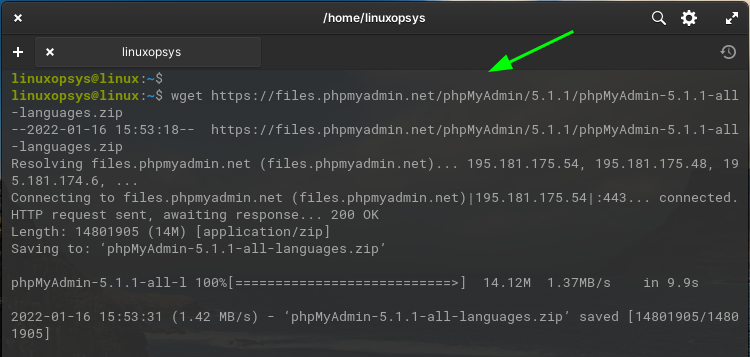
This command downloads the file phpMyAdmin-5.1.1-all-languages.zip to the current directory from the URL https://files.phpmyadmin.net/phpMyAdmin/5.1.1/phpMyAdmin-5.1.1-all-languages.zip.
To confirm use the ls command:
ls -l | grep -i phpmyadmin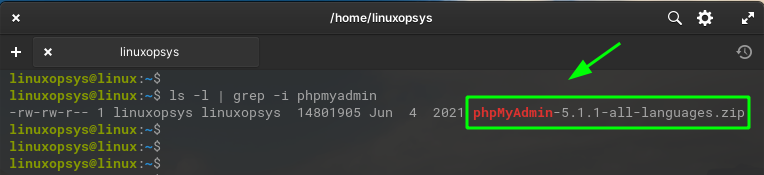
Save the file under a different name
Use the -O (uppercase 'O') option with wget command to specify the name of the file that will be saved on the local system. By default, wget uses the name in the URL. So this way once downloaded you can see the file has your custom name.
Example:
wget -O phpmyadmin.zip https://files.phpmyadmin.net/phpMyAdmin/5.1.1/phpMyAdmin-5.1.1-all-languages.zip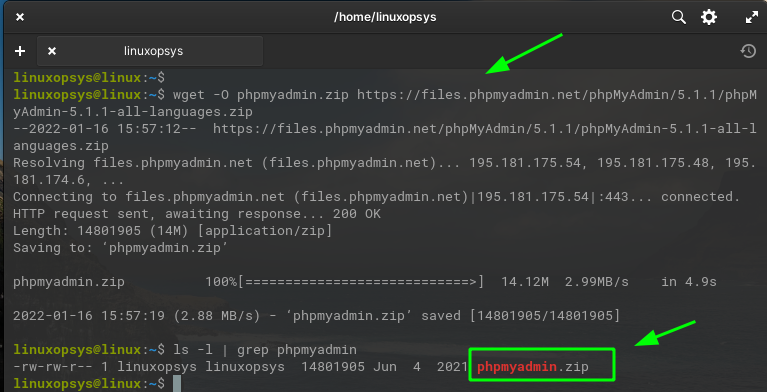
The name in the URL is phpMyAdmin-5.1.1-all-languages.zip, using the option we set the name phpmyadmin.zip to be saved as.
Downloading a file to a different directory
By default, wget downloads the file to the current directory. Use -P option with wget to specify a custom location for your download.
Example:
wget -P /tmp/ https://go.dev/dl/go1.17.6.linux-amd64.tar.gz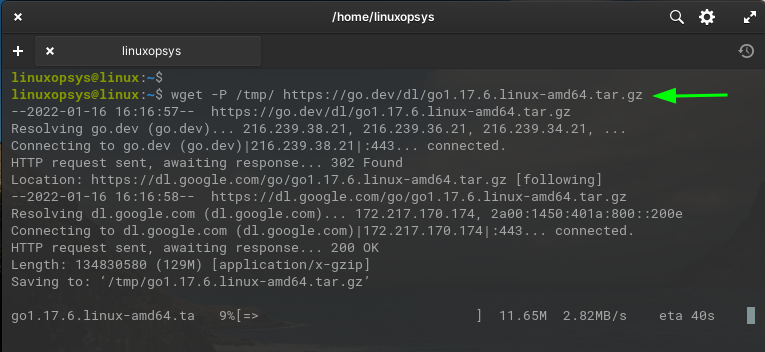
This command downloads the file go1.17.6.linux-amd64.tar.gz to the /tmp directory.
Usage Examples
Let's dig further into more usage examples of the wget command.
Downloading in Quiet Mode
When we run wget its outputs lots of information to the terminal. But you can use -q option to suppress all those outputs. So you can silently run the command.
Example:
wget -q https://en-au.wordpress.org/latest-en_AU.tar.gz
This downloads the WordPress tar.gz file to the current directory without any output to the terminal. This quit mode is often helpful when used in scripting.
Recursive Downloads
The wget --recursive or -r option allows to download files from specified URL and associated resources that URL links to. It continues this process recursively.
Example:
wget --recursive https://en.wikipedia.org/wiki/LinuxThis command will download the HTML file at the specified URL (https://en.wikipedia.org/wiki/Linux) and also follow all links within that file, downloading them as well.
By default wget --recursive would follow links back up to https://en.wikipedia.org but using --no-parent you can limit going back to the parent.
wget --recursive --no-parent https://en.wikipedia.org/wiki/Linux/You're telling wget to download everything from https://en.wikipedia.org/wiki/Linux recursively, but not to move up to https://en.wikipedia.org/wiki.
To download only specific file types using -A option with wget. Example:
wget --recursive -A gif,jpg https://en.wikipedia.org/wiki/Linux/This command will recursively download all .jpg and gif files from the specified URL.
Limiting the Download Speed
By default, the wget command uses up all the bandwidth to download files. This can be particularly useful when you're downloading large files or when you're on a slow connection.
To limit the download speed use the --limit-rate option followed by the value to limit. You can specify the speed in kilobytes per second (k), in megabytes per second (m) or gigabytes per second (g).
Example:
wget --limit-rate=1m https://go.dev/dl/go1.17.6.linux-amd64.tar.gz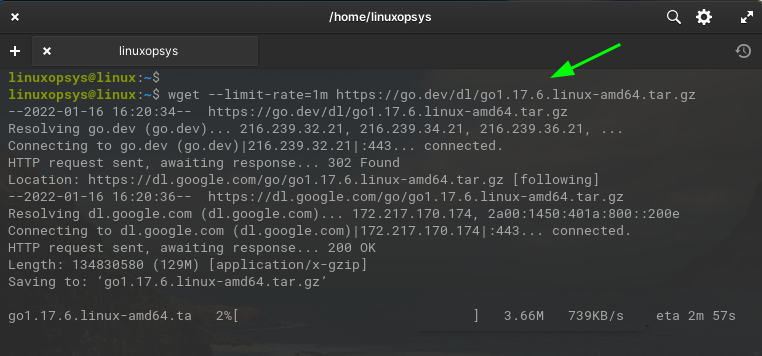
This command limits the download speed to 1 megabyte per second.
Resuming Interrupted Downloads
Occasionally, you will run into situations where the file download gets interrupted. This normally happens when downloading large files or when your network connection is unreliable. This creates a partially downloaded file. The wget provides a way to resume these interrupted downloads without having to start from the beginning.
In this example, we have simulated a failed file download by pressing Ctrl + C.
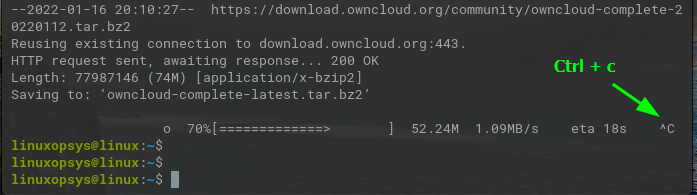
To continue the interrupted download use -c option with wget.
Example:
wget -c https://download.owncloud.org/community/owncloud-complete-latest.tar.bz2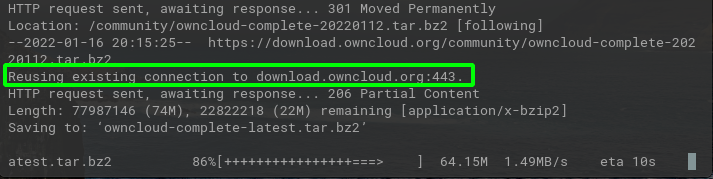
This command checks if the file with the same name exists in the current directory, If the file exists then wget sends Range headers to the server and asks servers to send data from where it was stopped.
Note: If the remote server doesn't support Range headers, it won't be able to send the remaining data, instead send the entire file again. Eventually overwrites the existing file.
Downloading Multiple Files
With wget use the -i (or --input-file) option followed by a file containing the list of URLs that you want to download.
Example:
wget -i download.txt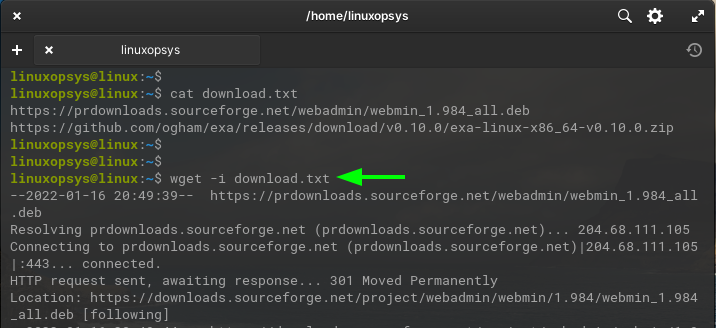
In this command, download.txt is a file that contains the list of URLs to download.
Mirroring Websites
You can download a mirror copy of a website using the -m option. Comes very useful if you want to view any website locally. It is technically equal to these options -r -N -l inf --no-remove-listing, meaning it enables recursion and time-stamping, sets infinite recursion depth, and keeps FTP directory listings.
Example:
wget -m https://example.com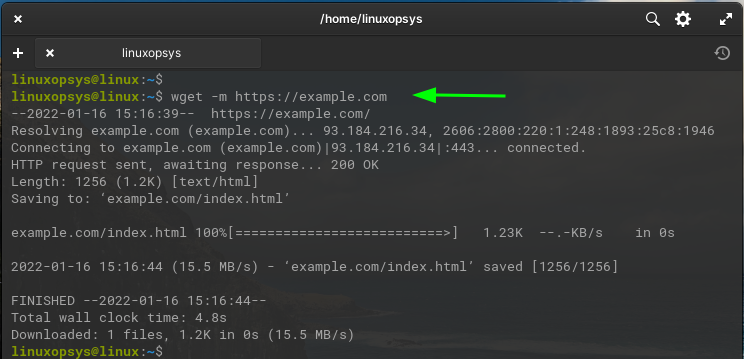
When mirroring a website consider adding the following options, which comes useful for fully experienced local browsing.
wget --mirror --convert-links --adjust-extension --page-requisites https://example.comWhere the additional options we added helps to :
--convert-linksor-k: This ensures that where possible, each link points to a locally downloaded equivalent. Basically, change the href to point locally.--adjust-extensionor-E: This option adds suitable extensions (.html or .css) to files (especially useful for dynamically generated pages).--page-requisites: This option makes wget download all the files necessary to properly display the page offline. This includes things like CSS style sheets, images, and other resources.
Keep a note: By default, wget follows the rules defined in robots.txt file. You can cautiously use the -e robots=off option to ignore it.
Downloading files in the background
Using wget we can download files in the background. This enables wget to start downloading files in the background and you can continue using the terminal or even close it.
Use -b option with wget to download files in the background.
Example:
wget -b https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.16.1.tar.xz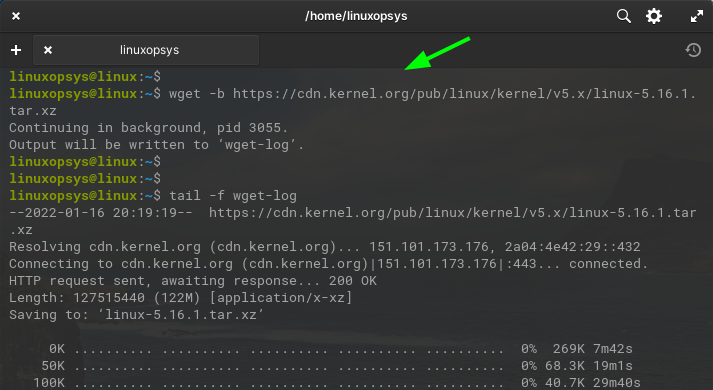
This command downloads linux-5.16.1.tar.xz file in the background. All the output will be logged into the wget-log file in the current directory. You can keep track of the download progress by viewing the wget-log file using the tail command.
If you want to specify a different log file, you can use the -o (or --output-file) option:
wget -b -o logfile.txt https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.16.1.tar.xzDifferent Protocols
You can use wget with different protocols such as HTTP, HTTPS, and FTP.
HTTP Example:
wget http://example.com/path/to/fileHTTPS Example:
wget https://example.com/path/to/fileBy default wget look for SSL certificate to verify. In some cases, you will find yourself downloading files from HTTPS sites with invalid or expired SSL. In those case we can tell wget to ignore these certificate errors by using the --no-check-certificate option. Example:
wget --no-check-certificate https://site-with-invalid-ssl-certificate.comFTP Example:
The wget command can also be used to download files from FTP servers
wget ftp://example.com/path/to/fileWhere a username and password are required, you can provide the username and password in the URL itself, or you can use the --user and --password options with wget.
wget --ftp-user=FTP_USERNAME --ftp-password=FTP_PASSWORD ftp://ftp.example.com/filename.tar.gzUsing wget with Proxies
The wget allows you to use a proxy server for your requests. You either set environment variables (https_proxy or ftp_proxy or set them in the wget configuration file.
Environment variable method:
export https_proxy=https://proxy-server:port/
wget https://example.comSetting in the configuration file:
You can either set it in the global configuration (/etc/wgetrc) or local (~/.wgetrc) file. Example
# ~/.wgetrc or /etc/wgetrc
https_proxy=https://proxy-server:port/You can also even try this oneliner from the terminal to download using a proxy:
$ http_proxy=https://proxy-server:port/ wget https://www.example.com/Note that the proxy settings in the wget configuration file will be overridden by the environment variables if they are set.
Logging Wget Output
Use -o option to log wget output to a file. You need to specify a filename, which will be created if doesn't exists. And will overwrite if it already exists.
Example:
wget -o wget.log https://en.wikipedia.org/wiki/Linux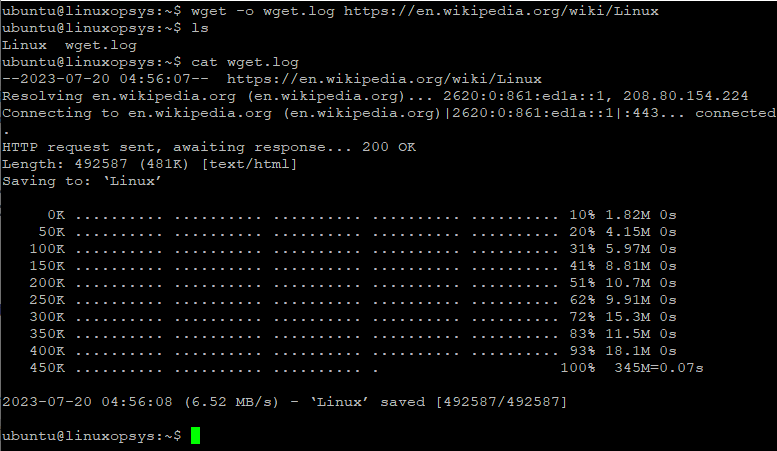
This downloads the webpage at https://en.wikipedia.org/wiki/Linux and write all output messages to a file named wget.log.
You may use -a option to append to the same file instead of overwriting. Example:
wget -a wget.log https://en.wikipedia.org/wiki/Linux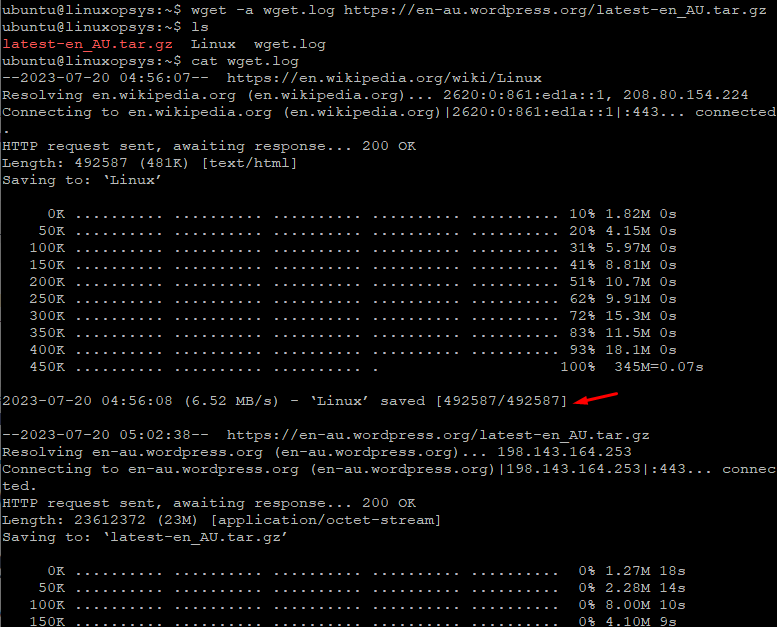
Change wget User-Agent
By default, wget sends a user agent string to identify itself to the server. Some servers block or limit these requests. Wget has an option named --user-agent which can be passed to pretend specific web browser.
Example:
wget --user-agent="Mozilla/5.0 (X11; Linux i686; rv:96.0) Gecko/20100101 Firefox/96.0" http://example.com
In this command, wget will send a user agent string that matches the one from a Firefox browser on a Linux machine.


Comments