
AWK is a versatile scripting language and command-line tool used in UNIX and Linux for processing and analyzing text files. It supports several variables, functions, and logical operators to get the desired output.
Key Features:
- Pattern Scanning and Processing:
- AWK excels in searching files for patterns and then performing specified actions on those patterns.
- It's often used for tasks like parsing logs, extracting columns from a CSV, or even for complex text manipulations.
- Support for Variables, Functions, and Operators:
- AWK has built-in variables (like
NR,NF,FS) and supports user-defined variables. - It includes a range of functions for string manipulation, arithmetic, and more.
- Logical operators in AWK (
&&,||,!) enable complex pattern matching and decision-making.
- AWK has built-in variables (like
Syntax
The basic syntax of the awk command:
awk [options] 'pattern {action}' file(s)[options]: These are optional flags that alter how AWK operates.pattern: This is the search pattern, telling AWK what to look for in the file. The pattern can be a string, a regular expression, or a range of lines. If omitted, AWK processes all lines.{action}: The action block contains the commands that AWK will execute when it finds a line matching the pattern. Actions are enclosed in curly braces{}. If no action is specified, the default action is to print the line.file(s): This specifies the file or files on which AWK will operate.
Sample File
We are using a sample file named emp_records.txt with the following content:
cat emp_records.txt
Firstname Lastname Age City EmpID
Bob Thomas 32 New York 80649
Steve Brown 29 Los Angeles 80521
David Miller 36 New York 80489
Travis Wilson 47 Chicago 65179
John Taylor 27 Boston 81440
Andrew White 41 Austin 75486Understanding Records and Fields in AWK:
- Records:
- In AWK, each line of the text file is considered a record.
- By default, records are separated by a newline character.
- You can modify the record separator using the
RSvariable.
- Fields:
- Fields are analogous to table columns and are separated by field separators (whitespaces, tabs, or other characters).
- Each field in a record is denoted by a dollar sign followed by a number (
$1,$2,$3, etc.), with$1being the first field,$2the second, and so on. $NFrefers to the last field in a record.$0represents the entire record.

AWK Command Examples
Let's first look into basic examples of awk command.
Default Behavior
The default behavior of the awk command is to print each line of data, until the end of the file, from the input file.
awk '{print}' emp_records.txt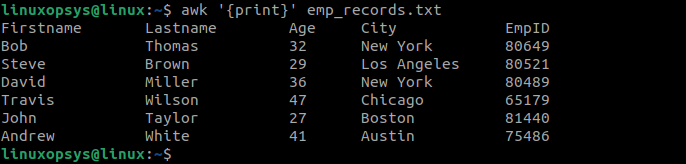
Basically prints the entire content of the file.
Print Specific Columns
You can specify specific column names to display or include in the awk output using the field numbers. For example, to print all records in the first column, type:
awk '{print $1}' emp_records.txt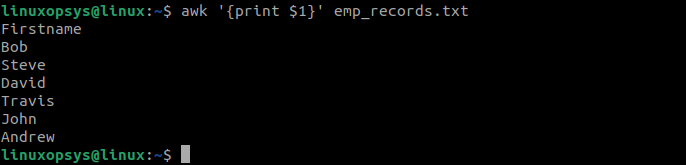
Instead, to print the entire records:
awk '{print $0}' emp_records.txtThis command prints each record (line) in the file.
Print Selected Fields
To print selected fields from a file, you specify the field numbers you want to extract. Each field in a line of text is typically separated by a delimiter (like a space or a comma), and awk allows you to access these fields using $1, $2, $3, etc., where $1 is the first field, $2 is the second, and so on.
Here's an example command to print the second and fifth fields from file named emp_records.txt:
awk '{print $2,$5}' emp_records.txt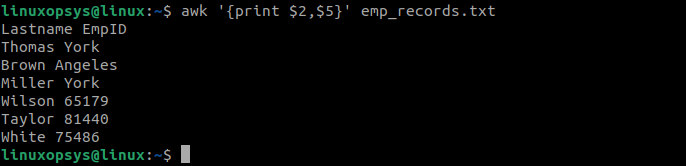
This command will print the second field (which could be 'Lastname' in a typical employee record) and the fifth field (possibly 'EmpID') of each line from the file.
Display Lines Matching a Pattern
To display lines in a file that match a specific pattern, you use a regular expression within the command.
Example:
awk '/^S/' emp_records.txt
This command will scan file for each line that starts with 'S', that entire line will be printed to the output.
Where the ^ is a regular expression anchor that matches the start of a line, and S is the character we're looking for at the beginning of the line.
Display Specific Lines of a Column
To display specific lines of a particular column from a file, you can extract the desired column and then pipe the output to other commands (like head, tail, grep) to filter specific lines.
Example:
awk 'print $3' emp_records.txt | head -1
This command displays the header (first line) of the third column in emp_records.txt.
Awk Built-in Variables
In addition to the variables we discussed before there are some more key built-in variables in Awk. Those are:
NR: Stands for "Number of Records". It keeps a count of the total number of input records processed so far.
awk '{print NR, $0}' emp_records.txtThis prints each line in emp_records.txt prefixed with its line number.
NF: Represents "Number of Fields" in the current record. It gives the number of fields in a line, which is helpful in processing column-based data.
awk '{print $1, $NF}' emp_records.txtThis prints the first field and the last field of each line.
FS: The "Field Separator" variable. It specifies the character used to separate fields in a record. The default is whitespace (spaces or tabs), but it can be set to any other character.
awk 'BEGIN {FS=":"} {print $1}' filename.txtIf filename.txt has fields separated by colons, this will print the first field of each line.
RS: Stands for "Record Separator". This variable defines the character that separates records. By default, it is the newline character, but it can be changed as needed.
$ cat sample.txt
USA, New York; Canada, Toronto; UK, London; Australia, Sydney; Germany, Berlin; Japan, Tokyo
$ awk 'BEGIN {RS=";"; FS=", "} {print "Country: " $1 ", City: " $2}' sample.txt
Country: USA, City: New York
Country: Canada, City: Toronto
Country: UK, City: London
Country: Australia, City: Sydney
Country: Germany, City: Berlin
Country: Japan, City: TokyoHere awk treats each semicolon-separated segment as an individual record and each comma-separated segment as individual fields within those records.
OFS: "Output Field Separator" is similar to FS but is used when printing the output. By default, it is a space.
awk 'BEGIN {OFS=" -- "} {print $1, $2}' emp_records.txt
Firstname -- Lastname
Bob -- Thomas
Steve -- Brown
David -- Miller
Travis -- Wilson
John -- Taylor
Andrew -- WhiteThis prints the first two fields of each record, separated by " -- ".
ORS: "Output Record Separator" defines the separator character used between records in the output. Its default value is a newline.
$ cat data.txt
Item1, Value1
Item2, Value2
Item3, Value3
$ awk 'BEGIN {ORS=" | "; FS=", "} {print $1, $2}' data.txt
Item1 Value1 | Item2 Value2 | Item3 Value3 |Each pair of item and value is printed, followed by the custom record separator.
Advanced Examples
Regular Expressions in awk
Regular expressions (regex) in AWK allow you to specify complex criteria for matching strings in records.
Basic Syntax:
awk ‘/regex/ {action}’ input_fileThe regex pattern for awk is surrounded by two slashes (/ /).
To display the first field of every record that starts with S, you run the following command:
awk ‘/S/ {print $1}’ emp_records.txt
Relational Expressions
Usage: To match content of a specific field using a pattern.
The default behavior of the awk command is to check regex against all the records. However, relations expressions can be used to check against a field using the contain (~) comparison logical operator.
Print the last name of employees whose age is 47:
awk '$3 ~ /47/ {print $2}' emp_records.txt
Range Pattern in awk
Usage: To select a range of records starting from a match to another match.
Print employee IDs from records starting with "Chicago" and ending at "Austin":
awk '/Chicago/, /Austin/ {print $5}' emp_records.txt
Conditional Searches in AWK
Usage: To perform actions based on if-else conditions.
Example: If employee ID is greater than 80000, print first name, else print 0:
awk '{if ($5 > 80000) {print $1} else {print "0"}}' emp_records.txt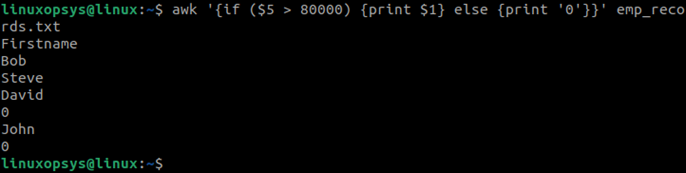
Processing Output from Other Commands
Usage: AWK can process the output of other shell commands.
Retrieve IP addresses from ip addr output:
ip addr | awk '/inet / {print $2}'
Combining Patterns with Logical Operators
Usage: To use AND (&&) and OR (||) for complex pattern matching.
Print employee IDs of all employees whose age is between 35 and 50:
awk '$3 > 35 || $3 < 50 {print $5}' emp_records.txt
BEGIN and awk END Blocks in AWK
The awk command supports two special patterns- BEGIN and END patterns.
The BEGIN block instructs awk to take certain actions before all other records are processed and the END block requires awk to take certain actions after all other records are processed.
awk 'BEGIN { FS=","; print "Start of Processing" } {print $1}' filenameThis script sets the field separator to a comma and prints a message before processing any data in filename.
awk '{sum += $1} END { print "Total:", sum }' filenameThis script calculates the sum of the values in the first field of each record and then prints the total sum after processing all records.
Combined BEGIN and END Blocks
The following example add a custom message before and after processing the first field of all the records:
awk 'BEGIN {print "First Record."}; {print $1}; END {print "Last Record."}' emp_records.txt


About The Author
Subhash Chandra

Subhash Chandra, an Oracle Certified Database Administrator and professional writer, works as a Consulting User Assistance Developer at Oracle, bringing over 15 years of experience to the role. He enjoys sharing his technological passion through how-to articles, simplifying complex concepts in Linux, Windows, Mac OS, and various other platforms and technologies for a wide audience.
Comments