
Checking the number of lines in a file becomes important for file validations, monitoring, debugging scripts, and optimization. When working with large amounts of data or log files, you can estimate the file size by getting an idea of the number of lines it has. In this tutorial, we will learn how to count the number of lines in a file using Bash.
1. Prerequisites
Let us assume we have a text file sample.txt with the following contents
Paris - France
Berlin - Germany
Vienna - Austria
Warsaw - Poland
Olso - Norway
London - England
Rome - Italy
Madrid - Spain
2. Using the wc Command
The wc command is a built-in command line utility to get the statistics of any file. This may include the number of lines, words, and characters. It stands for Word Count. It is the most widely used tool for counting purposes.
Syntax:
wc [option][file]| Options | Description | Example |
|---|---|---|
| -c | Displays the number of characters in the file. | wc -c sample.txt |
| -w | Displays the number of words in the file. | wc -w sample.txt |
| -l | Displays the number of lines in the file. | wc -l sample.txt |
| Displays the number of characters, words and lines in the file, if no option is provided. | wc sample.txt |
Example:
wc -l sample.txt
cat sample.txt | wc -l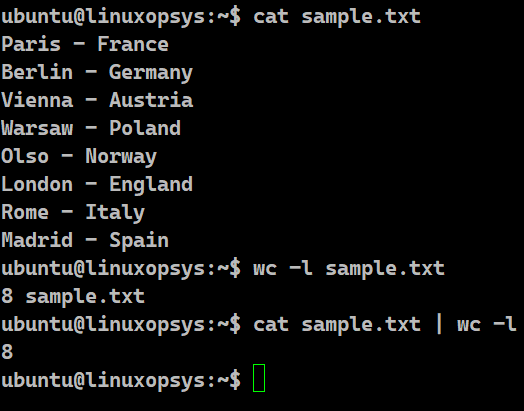
In this example, we have taken the input file as sample.txt. We are displaying the total number of lines present in this file using the wc command. In the first case, we get the result along with the name of the file. Sometimes, all we need is just the number of lines. For that, we can pipe the result of the cat command so that it acts as an input to the wc command. The cat command on sample.txt would display the contents of the terminal. Since there is a pipe symbol, it is being fed as an input to the wc -l command which will display the total number of lines.
3. Alternate methods
With Bash, we have different approaches to getting the line count of a file. We can do this without having to open it in a text editor.
3.1. Using cat command
The cat command stands for concatenate. It is used to display the output on the terminal. However, we can display the number of lines as well.
Syntax:
cat -n [file]Example:
cat -n sample.txt
cat sample.txt | grep -c ^
cat sample.txt | wc -l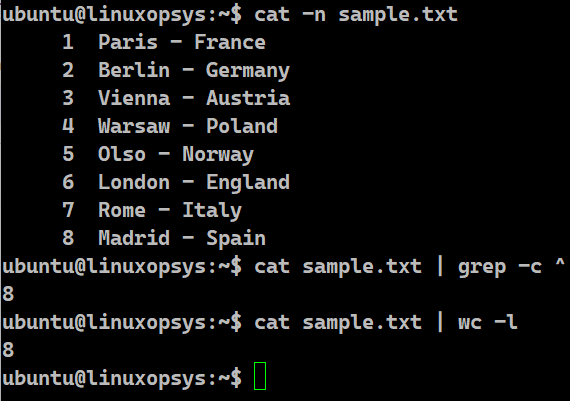
We can pass the -n flag available with the cat command to display the line numbers along with the lines. It will display the line numbers and the corresponding line starting from the first one. This approach is not a good one if the file is huge. The other option is to combine cat with powerful tools like grep or wc command. In the next two lines of this example we are piping the result of the cat command so as to feed it as input to the grep and wc command respectively.
3.2. Using grep Command
The grep command is used primarily to look for the occurrence of a pattern or a string in a file. It is an abbreviation for Global Regular Expression Print. We can use the -c option to count the number of such occurrences.
Syntax:
grep -c [pattern] [file]Example:
grep -c ^ sample.txt
grep -c ".*" sample.txt
grep -c "$" sample.txt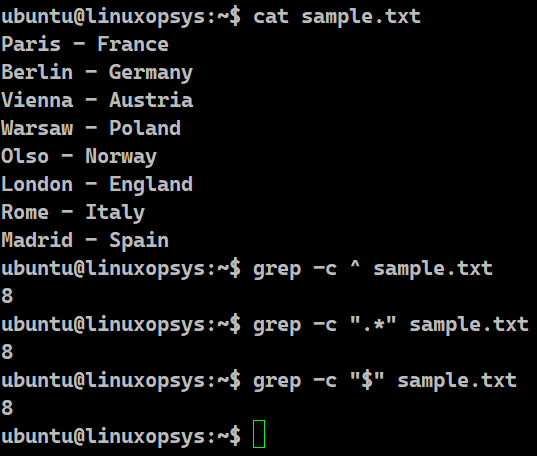
In all three cases of this example, we are using grep with the -c option to count the occurrence of a pattern. The ".*" is used as a regular expression to find out the strings in the file. The caret (^) symbol is another regular expression that signifies the beginning of the line. Hence, if there is any character in the file, we can use this symbol. Similarly, we use the dollar ($) symbol for the end line of the regular expression. In every case, we are counting the number of such patterns. These patterns simply denote the lines. With the -c option we are getting the total number of lines present in the sample.txt
3.3. Using awk command
The awk command is an extremely powerful and useful tool to process texts, including finding the total number of lines present in a file.
Syntax:
awk 'END {print NR}'[file]Example:
awk 'END {print NR}' sample.txt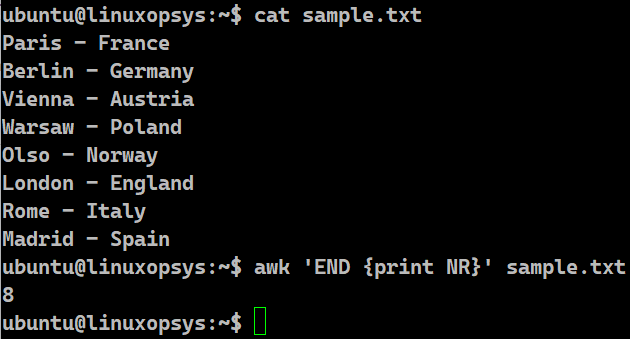
The reason the awk command works efficiently is because it treats every line as a record. We can print the number of lines by using its built-in NR variable in the END section. This special variable holds the current line number. Once the entire file has been processed, it will hold the total number of lines of that file. In our case, we will get the result as 7.
3.4. Using sed command
Like awk, sed is an equally powerful tool. It stands for Stream Editor. It can carry out basic text transformation on any file. It can give us the total number of lines present in a file as well.
Syntax:
sed -n '=' [file]Example:
sed -n '=' sample.txt
sed -n '$=' sample.txt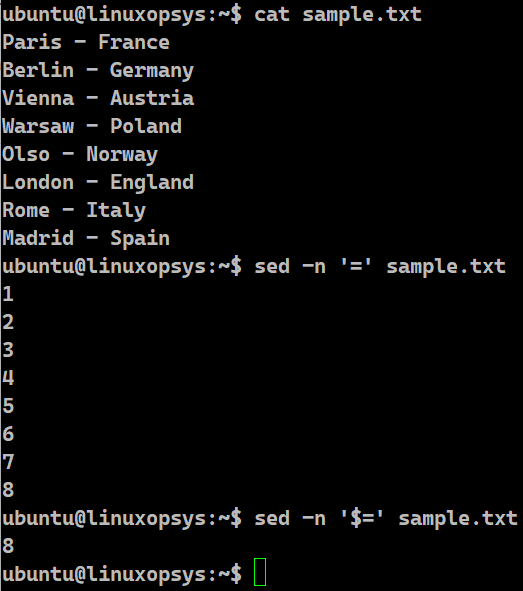
In the first case, the sed command, with the -n option, and an equal sign prints the line numbers without the content of the file. The line numbers begin from 1. Hence, this approach isn’t appropriate for large files. We often prefer just the final number. In the next case, we used the sed command with the same -n flag but with the $= operator. This ensures that the output is the last line number of a file.
3.5. Using a while loop
We already know how to read a file line by line using while loops. We can use this technique to get the total number of lines in a file. We need to maintain a counter and keep on incrementing it as we read the file.
Example:
#!/bin/bash
count=0
while read line
do
count=$((count+1))
done < sample.txt
echo Number of lines: $count
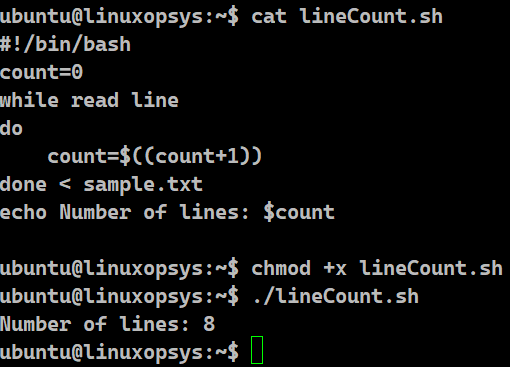
In this example, we have initialized a variable to zero. This variable is responsible for maintaining the number of lines read so far. For each iteration of the while loop, the read command reads that particular line of the file and assigns it to the bash shell variable $line. In every iteration, we are incrementing the value of that count variable by 1. The loop runs till the number of lines in the file. After reading the last line of the file, the while loop stops. At this time, we will have the total number of lines present in sample.txt stored in the variable count. Upon echoing that variable, we get the final count.
4. Counting Lines in a Single File
We can use any of the methods described to find the total number of lines present in a file. The below examples will list the total number of lines present in the sample.txt file. The grep command is typically fast. We should use the grep command if the file is huge.
Example:
wc -l sample.txt
cat sample.txt | grep -c ^
cat sample.txt | wc -l
grep -c ^ sample.txt
grep -c ".*" sample.txt
grep -c "$" sample.txt
awk 'END {print NR}' sample.txt
sed -n '$=' sample.txt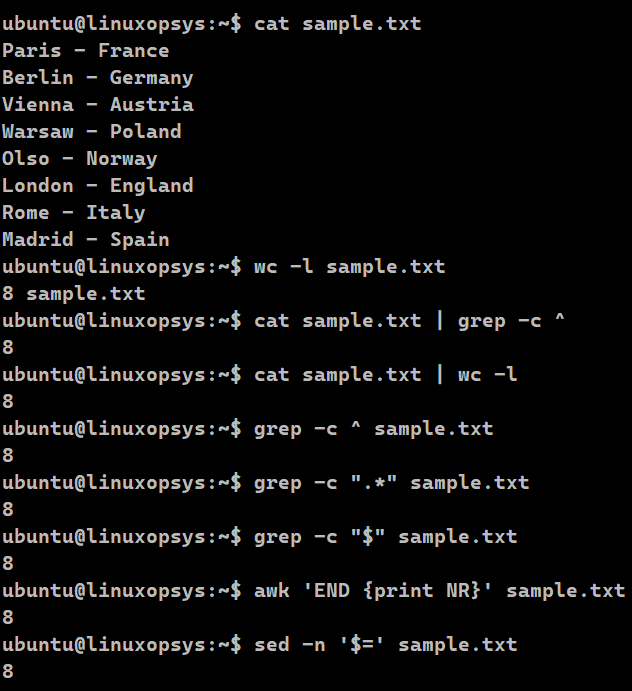
5. Counting Lines in Multiple Files
In Bash, we can also get the count of the total number of lines of more than one file. We do not need to write the same command again and again for each file.
Example:
wc -l sample.txt sample1.txt
grep -c ^ sample.txt sample1.txt
sed -n '$=' sample.txt sample1.txt
awk 'END {print NR}' sample1.txt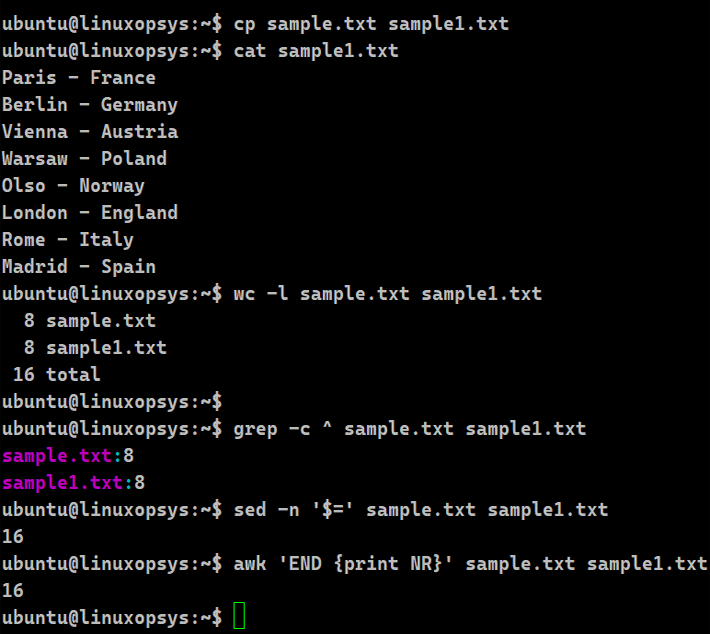
We have taken the wc command with the -l option to get the line numbers. We can supply multiple files separated by a space to the wc command to get the number of lines in each file. The wc command does an additional calculation of finding the total number of lines in all the specified input. In our case, sample.txt and sample1.txt each have 8 lines. Upon executing the wc -l command on these two files, we get the number of lines in each of the files along with the final total as 16. Similarly, if we use the awk or the sed command with multiple files, we will again get 16.
The grep command can also take multiple files as input. It will also give the individual line count of the files. The "^" represents the beginning of the regular expression and "-c" denotes the count option.
Which one should we use? Generally, for bulky files, grep command will work much faster than the wc command
6. Excluding Lines from Counting in Bash
With Bash, we have the flexibility to exclude certain lines while calculating the total number of lines. We can use the grep command with the -v option for this.
Example:
grep -cv '^L' sample.txt
grep -v '^L' sample.txt | wc -l
grep -cv '^$' sample.txt
grep -cv '^#' ~/.bashrc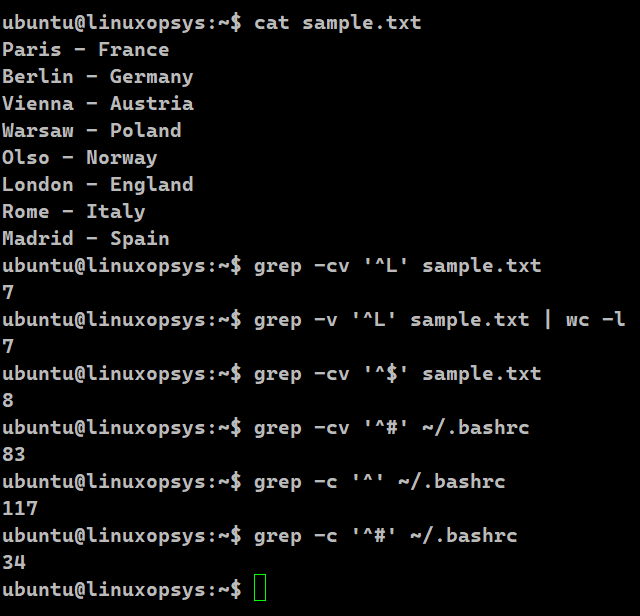
In this example, we have used the -v flag with the grep command. This flag inverts the sense of matching. When used, it selects the non-matching lines. In the first case, we are looking for lines that do not begin with the letter "L". We also have the -c flag to count such occurrences. As we have one such line beginning with L, the outcome is 7.
In the next case, we are doing the same thing but piping the result to provide it as an input to the wc -l command. Naturally, this operation will be slower than the first one since multiple steps are involved.
The third case is pretty common. It is used to exclude blank lines when counting the total number of lines in the input file. The final case looks for the lines that beginning with # and excludes them. This case is often used to count uncommented lines of configuration files like the bashrc. In our case as well, we are counting the number of lines in bashrc that do not begin with a comment.
7. Saving Line Counts to a file
With Bash, redirecting the output to a file is straight-forward. We can use the redirection operators.
Example:
wc -l sample.txt > result.out
cat result.out
wc -l sample.txt >> result.out
cat result.out
wc -l sample.txt | tee result.out
cat result.out
out=`cat sample.txt | wc -l sample.txt`
echo Number of lines: $out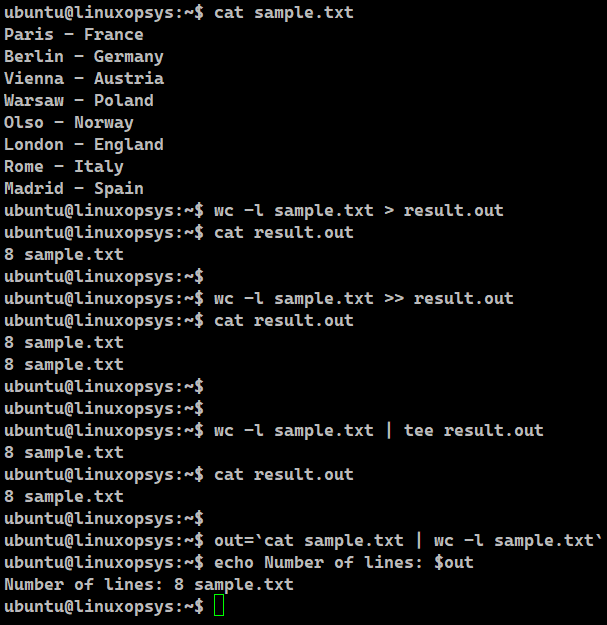
In the first two wc commands the output will not be displayed on the terminal. This is because we are using the redirection operators to redirect the standard output to the file. The operator > differs from >>. The latter ensures that the file is appended with the entry. However, the former overwrites the file completely before entering any information in the file.
The tee command is another tool that ensures that the output appears on the terminal as well as the text file. We can save the output in a variable as well. Here, we have made use of the backticks (`).
Conclusion
- We can use different approaches to count the lines in a file.
- Certain utilities like grep and wc can work on multiple files.
- The grep command can be used with regular expressions and is much faster than the wc command.
- We can also exclude certain patterns while calculating the line numbers of a file.
- We can store the result of the count in a variable or redirect it to a file.


Comments